Better handle the pre-time path population distribution#1073
Better handle the pre-time path population distribution#1073jdebacker wants to merge 19 commits into
Conversation
Codecov Report❌ Patch coverage is
Additional details and impacted files@@ Coverage Diff @@
## master #1073 +/- ##
==========================================
+ Coverage 73.09% 73.19% +0.09%
==========================================
Files 21 21
Lines 5208 5186 -22
==========================================
- Hits 3807 3796 -11
+ Misses 1401 1390 -11
Flags with carried forward coverage won't be shown. Click here to find out more.
🚀 New features to boost your workflow:
|

|
All local tests pass: |
|
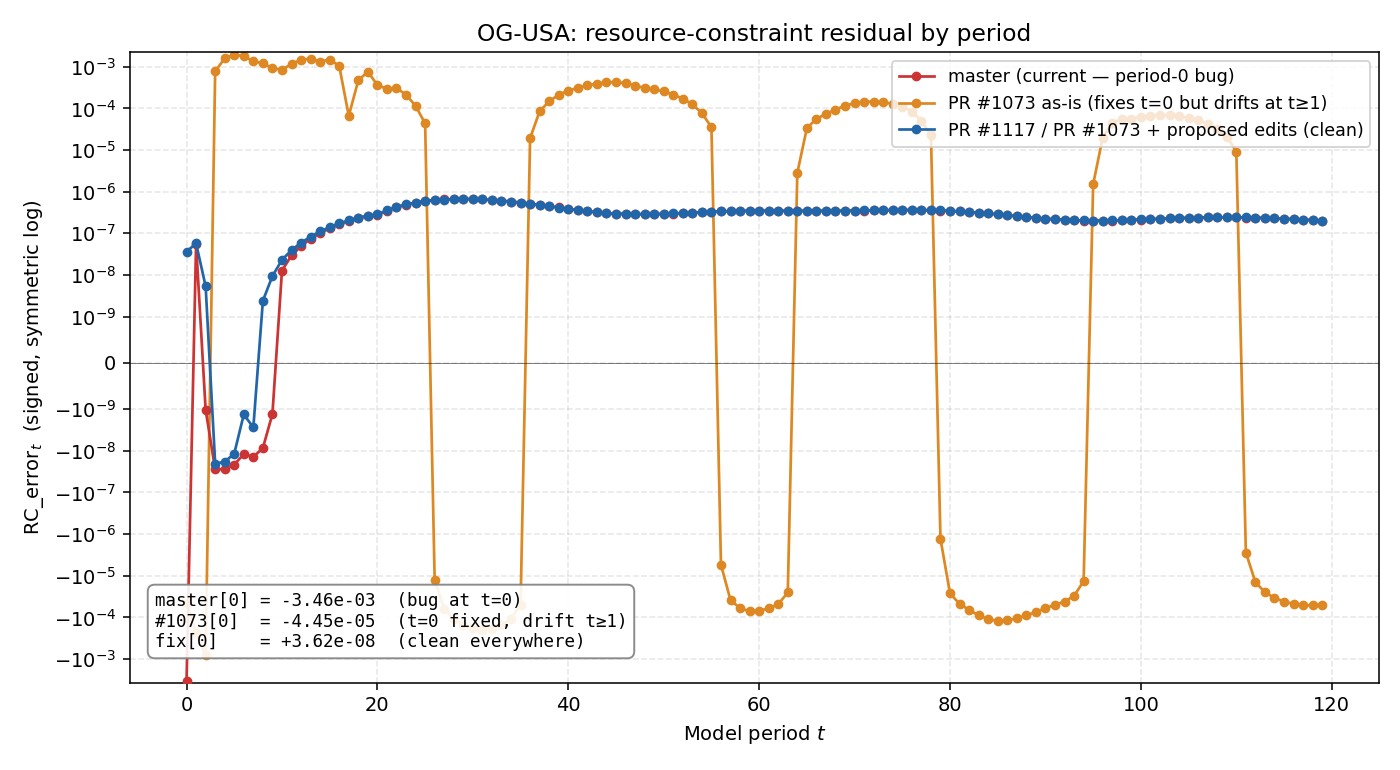
When running the OG-USA example (and updating the demographic parameters), I find the following resource constraint issues: OG-Core built from the
|
|
@rickecon Can you review these changes and see if you can pinpoint where the new RC errors are coming from? I've gone over these changes manually several time and have had Codex and Claude Code agents trying to diagnose, but not luck. Here's what my run of OG-USA with updated demographics looks like (snippet of how set the baseline, which is the only thing of interest here): """
---------------------------------------------------------------------------
Run baseline policy
---------------------------------------------------------------------------
"""
# Set up baseline parameterization
p = Specifications(
baseline=True,
num_workers=num_workers,
baseline_dir=base_dir,
output_base=base_dir,
)
# Update parameters for baseline from default json file
with importlib.resources.open_text(
"ogusa", "ogusa_default_parameters.json"
) as file:
defaults = json.load(file)
p.update_specifications(defaults)
p.tax_func_type = "HSV"
p.age_specific = True
c = Calibration(p, estimate_tax_functions=False, estimate_pop=True, client=client)
d = c.get_dict()
# # additional parameters to change
updated_params = {
"omega_S_preTP": d["omega_S_preTP"],
"omega_SS": d["omega_SS"],
"omega": d["omega"],
"g_n_ss": d["g_n_ss"],
"rho": d["rho"],
"g_n": d["g_n"],
"imm_rates": d["imm_rates"],
"g_n_preTP": d["g_n_preTP"],
"imm_rates_preTP": d["imm_rates_preTP"],
"rho_preTP": d["rho_preTP"],
}
p.update_specifications(updated_params)
# Run model
start_time = time.time()
runner(p, time_path=True, client=client)
print("run time = ", time.time() - start_time) |
|
@jdebacker @rickecon: I dug into the period-1+ drift you flagged. The boundary fix idea is right — master does have a real period-0 inconsistency — but the drift across the rest of the path is coming from how growth rates are indexed in this branch. In master, You can confirm this without running the model. The population accounting itself fails the consistency check across t=1 to fixper, in the exact shape you reported. The reindex is a one-line revert. But this PR also bundles other changes that aren't strictly part of the boundary fix — the timeline extension, the slicing on returned arrays, the new |
|
Opened #1117 with the smaller version. |
|
@jdebacker — here's what I think is going on and why you're seeing that drift. This PR changes one line in The drift is caused by The transition-path updates would be:
(The test expected values in cc @rickecon |
|
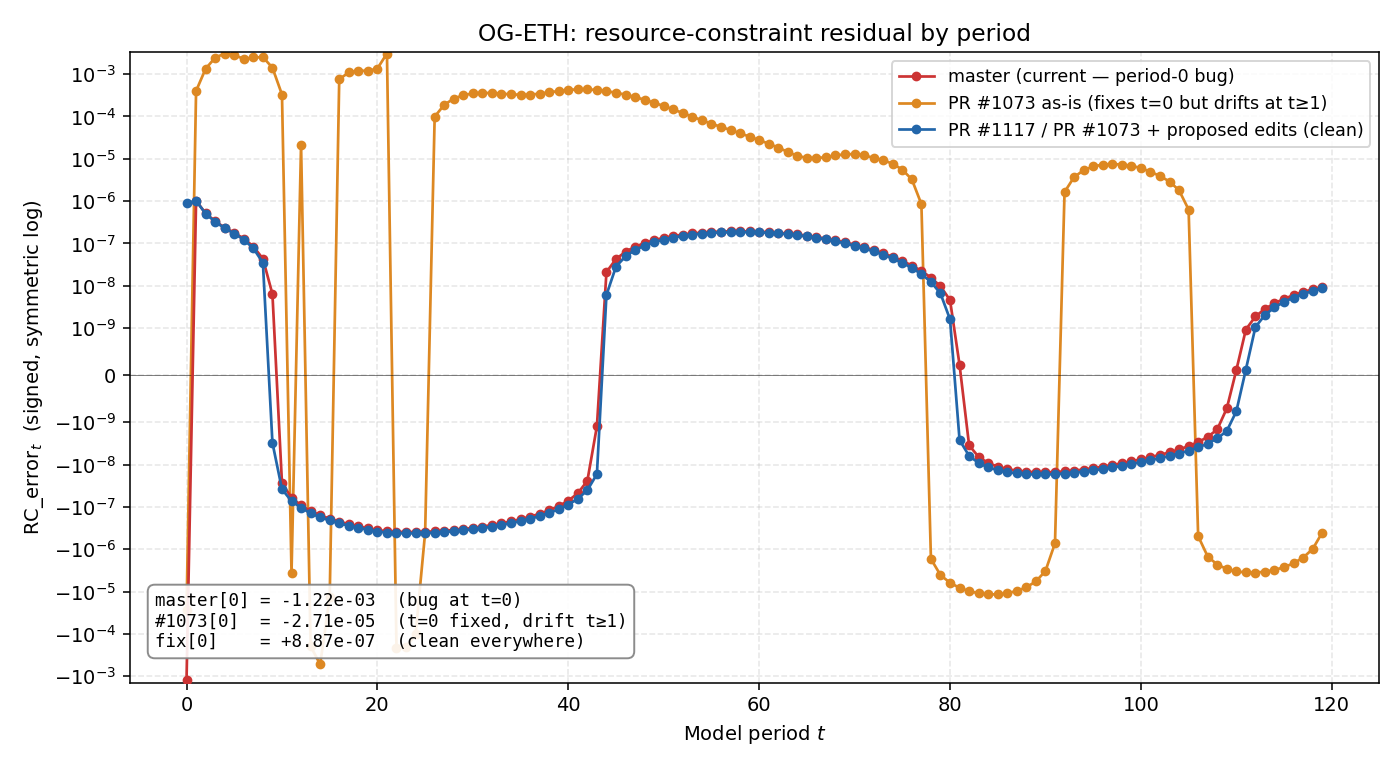
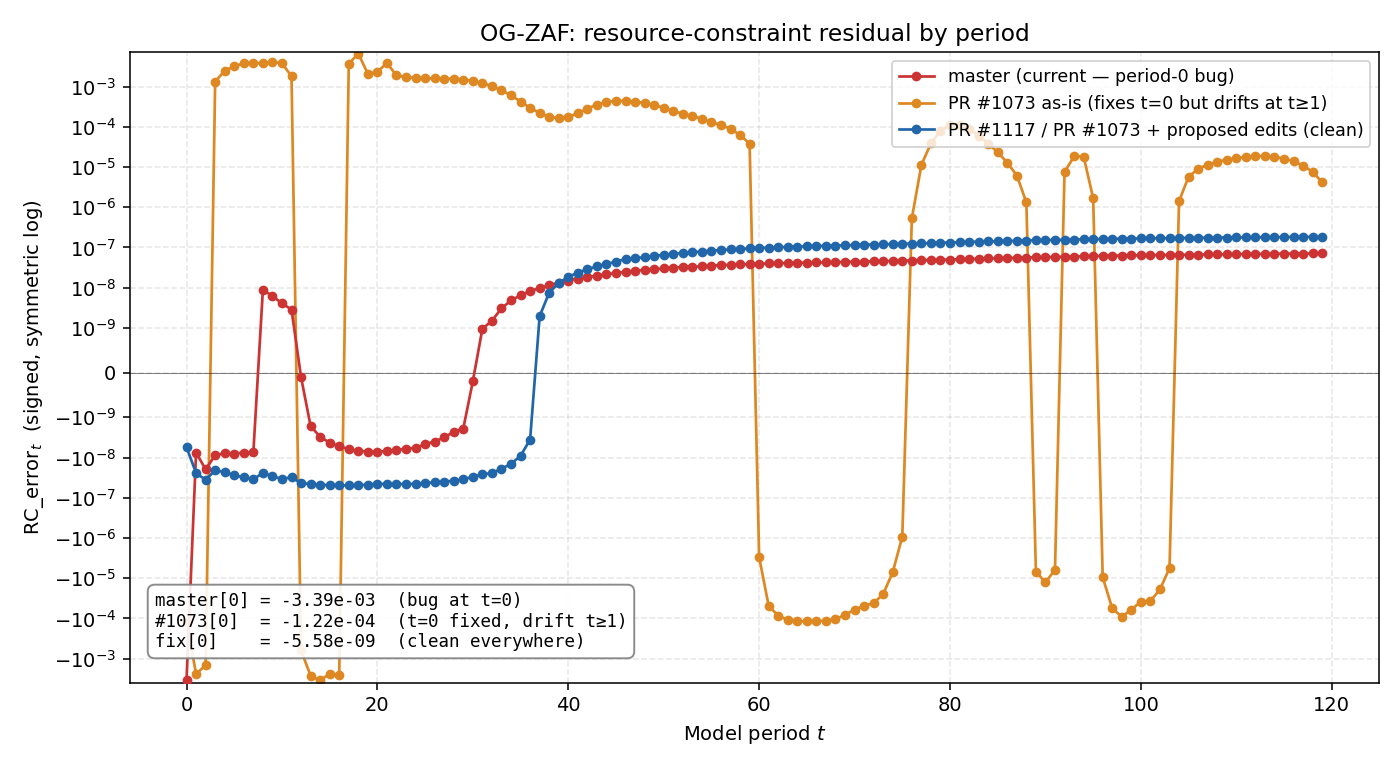
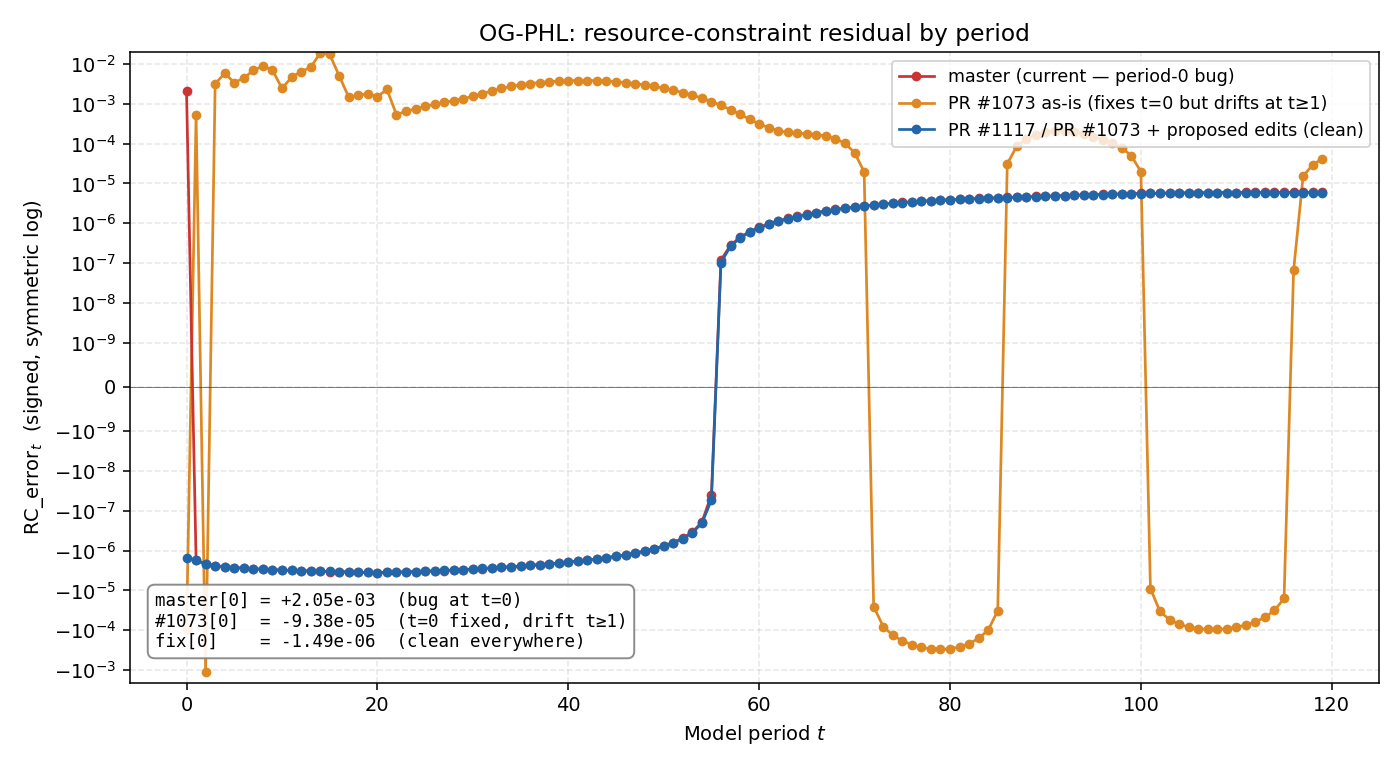
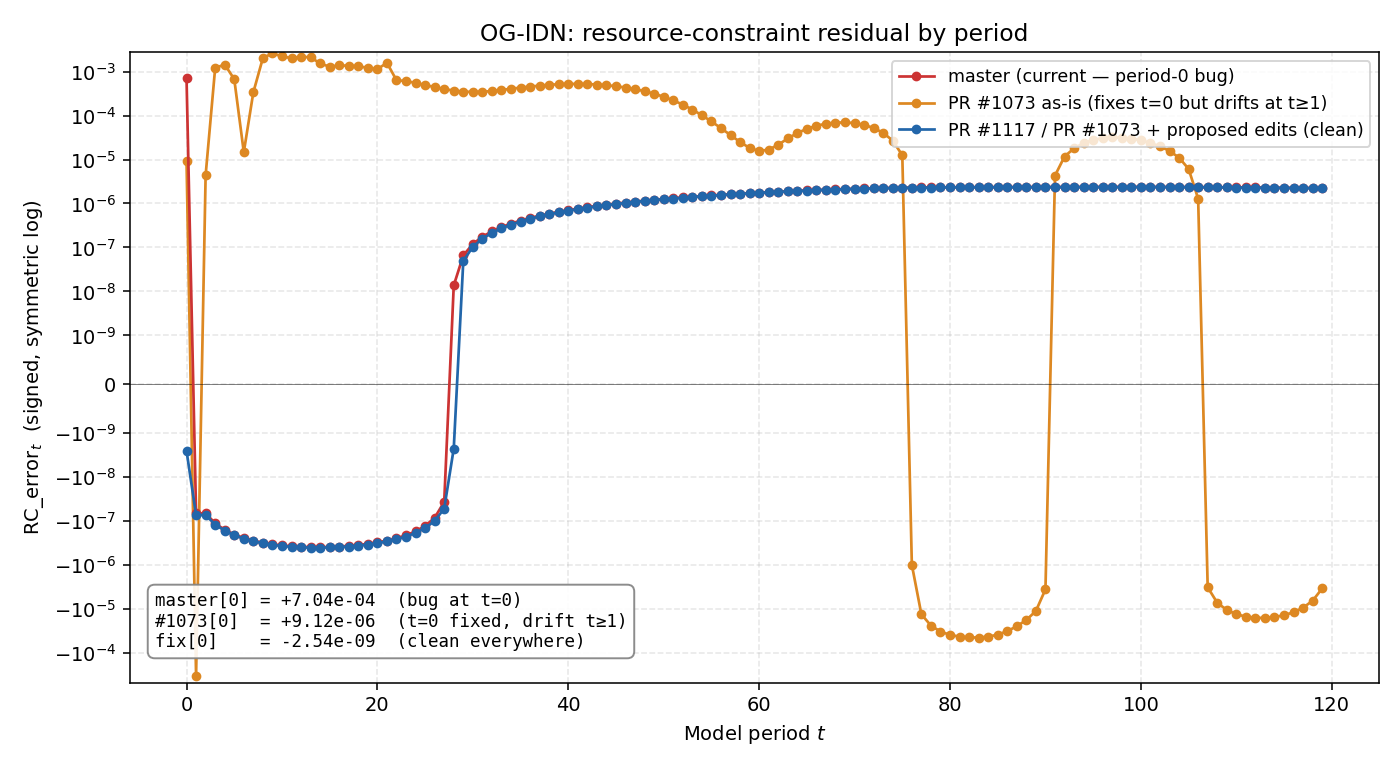
Following up on our offline discussion. Ran the boundary fix end-to-end in all 5 country repos — full TPI baselines, each with its own Three branches tested per country:
Master (red) has the t=0 boundary inconsistency and is clean at t≥1. PR #1073 as-is (orange) fixes t=0 but introduces sustained drift at t≥1 — trading one error for another, which is the issue you reported on OG-USA in December. With the
How to apply the fix in this PR. Six line edits in
Plus the expected-value calculations in These changes are all in OG-Core — no per-country PRs needed. Every downstream country repo runs Test setup per country. Loaded each country's This PR (#1073) is the cleaner shape — pulling the boundary value out at the source rather than layering it through I don't have push access to this branch, so #1117 is my fallback with the same math. I'll post the same results there. |
||||||||||||||||||||||||||||||
The population distribution before the start year of the model is necessary to compute savings and bequests in period 0.
This PR adds explicitly the parameters for mortality, immigration, and population growth rates from period 0 to period 1 in order to make for a consistent transition from this "pre model period" to period 0.
cc @rickecon